Title here
Summary here
April 13, 2026 in agents, architecture by Odelia Cohen6 minutes
An exploration of the structural limitations of text-based RAG systems, supported by benchmarks, and how Rich mode introduces a multimodal retrieval strategy that preserves and leverages images as first-class evidence.
In a RAG system, a fundamental constraint quickly emerges: everything must ultimately be reduced to text.
Retrieval relies on textual representations, vectorization indexes text, and language models primarily reason over text. This means that even when documents contain rich visual elements — slides, diagrams, screenshots — those elements must be transformed into text (via OCR, captions, or descriptions) to become usable.
Medium mode was designed to address this limitation. By introducing a vision layer during ingestion, it improves the quality of extracted content and enriches the textual representation of documents. In practice, this leads to better structure, better segmentation, and more informative chunks.
However, this approach remains fundamentally constrained.
No matter how advanced the vision enrichment becomes, the system still operates within a text-first paradigm. Visual information is translated, compressed, and approximated into text before being used. This introduces an unavoidable loss of fidelity.
This is the limit we wanted to challenge.
To better understand its impact, we conducted an internal benchmark comparing two approaches:
To ensure a fair comparison, both pipelines were evaluated on the same dataset and under identical conditions.
The evaluation was conducted on a dataset of 10 images, covering different types of visual content:
For each image, 3 questions were defined, resulting in a total of 30 questions per pipeline (60 responses overall).
The outputs were then evaluated according to the following criteria:
Accuracy
Does the model’s answer match the expected answer? (factual correctness)
Relevance
Does the answer actually address the question? (whether the response answers the question asked, beyond being correct)
Visual fidelity
Does the answer correctly describe the visual elements without introducing hallucinations?
Grounding
Is the answer supported by elements explicitly visible in the image (text, objects, spatial relations)?
Latency / cost
How efficient is the pipeline in terms of response time and processing complexity?
Each response was scored using a predefined evaluation grid.
It is important to note that this evaluation was conducted manually (human-in-the-loop). While care was taken to ensure consistency and objectivity, some degree of subjectivity remains.
As a result, these metrics should be interpreted as observed trends rather than absolute measurements.
The results were unambiguous.
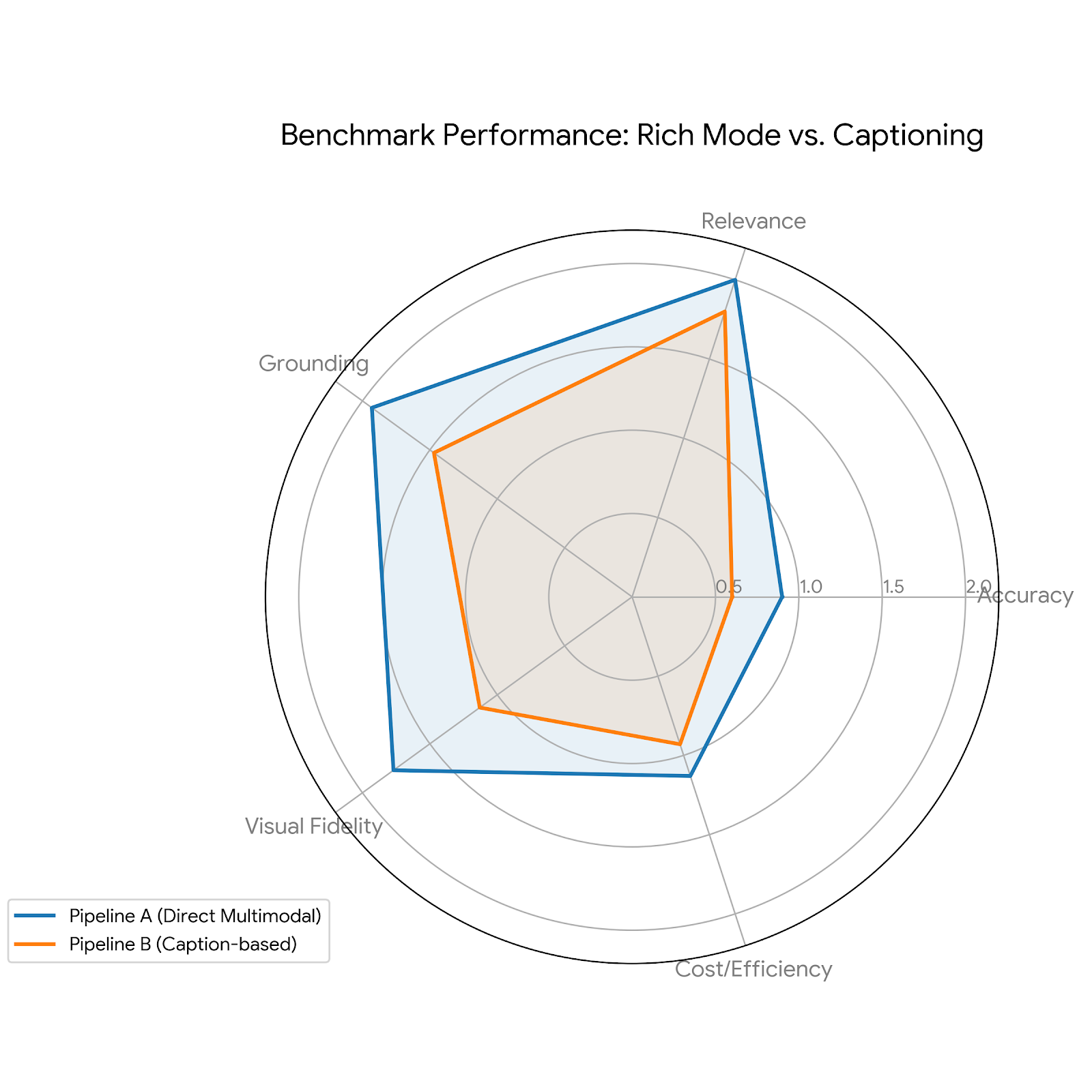
Each metric reported corresponds to the average score across all evaluated samples. While Pipeline B (Caption-based) introduces interpretation bias during the “image-to-text” phase, Pipeline A (Rich Mode) maintains higher grounding and visual fidelity by bypassing the translation layer. For the record here are the results:
| Metric | Pipeline A (Direct Multimodal) | Pipeline B (Caption-based) |
|---|---|---|
| Accuracy | 0.90 | 0.60 |
| Relevance | 2.00 | 1.80 |
| Grounding | 1.93 | 1.47 |
| Visual Fidelity | 1.77 | 1.13 |
| Cost / Efficiency | 1.13 | 0.93 |
| Average Latency | 4.35s | 5.05s |
| Total Score | 7.37 / 9 | 5.93 / 9 |
While the dataset remains limited, the consistency of the gap across all metrics highlights a structural advantage of direct multimodal processing over text-based approximations. Even when correct, the intermediate description tends to enrich or reinterpret the image, injecting information that is not strictly present. This bias propagates into the final answer and degrades its fidelity.
In other words, improving the text is not enough if the problem comes from reducing the image to text in the first place.
This observation led to a shift in approach.
Rather than continuing to refine the transformation of images into text, Rich mode introduces a different paradigm: reintroducing the image itself at inference time.
Instead of relying solely on a textual approximation, the system:
When relevant, these images can then be re-injected into the multimodal model during answer generation.
This allows the system to combine two complementary strengths:
Rich mode does not replace the existing RAG pipeline. It extends it.
It acknowledges a structural limitation of text-based systems and introduces a controlled way to bypass it, using images as high-fidelity evidence when needed.
In that sense, Rich mode is not just a more advanced ingestion strategy. It is a shift in how information is preserved, retrieved, and ultimately used by the system.
RAG systems have historically been built around a simple principle: transform documents into text, split them into chunks, index them, and retrieve them at query time.
This approach remains effective in many cases, but it quickly reaches its limits when documents contain structurally important visual information.
This is especially true for slide decks, complex PDFs, screenshots, charts, or diagrams. In such formats, a significant portion of the information does not reside purely in text, but in visual structure, layout, and spatial relationships between elements.
To address this limitation, recent approaches have evolved toward systems capable of directly processing images, without systematically relying on an intermediate transformation into text.
Modern multimodal models — both proprietary and open source — now integrate vision natively. Images are no longer simply converted into textual descriptions, but are directly processed by the model at inference time.
This allows for better preservation of information and reduces the loss introduced by text-based transformations.
However, this evolution does not fully solve the problem in a RAG context.
While image understanding is now well handled at generation time, retrieval systems still rely heavily on textual representations. This creates a gap between the model’s ability to understand visual content and the way this content is stored and retrieved.
This gap is reflected in the approaches adopted by leading actors in the field:
| Actor | Image Processing | Document Handling | RAG Approach | Strengths | Limitations |
|---|---|---|---|---|---|
| OpenAI (GPT-4o) | Native multimodal processing | Combined text + image analysis | Mostly text-based retrieval | Strong direct image understanding | Limited explicit multimodal RAG tooling |
| Google (Gemini + Document AI) | Multimodal + structural analysis | Structure-aware (layout, tables, figures) | Hybrid (text + structure + visual) | Advanced document understanding | More complex pipeline |
| Anthropic (Claude) | Direct image processing | PDF treated as text + image | Oriented toward direct understanding | Strong visual reasoning | Limited industrialized multimodal RAG |
| Open source (LLaVA, etc.) | Visual encoder + LLM | Explicit image → representation pipeline | Evolving toward multimodal RAG | Transparency and flexibility | Lower performance |
This table represents a synthesis of publicly available documentation and observed architectural patterns, rather than a strict feature-by-feature specification.
A consistent pattern emerges from this comparison: while leading models are now capable of native multimodal understanding, retrieval systems still rely predominantly on text to organize and access information.
As a result, the most advanced approaches do not attempt to replace text entirely, but rather to complement it. They combine multiple layers of representation — textual content, document structure, and visual information — in order to reduce information loss and improve the grounding of generated responses.
This is precisely the space where Rich mode operates.